hexo 升级
hexo已经几年没用过了,临时想用一下发现依赖版本已经落后太多,无法运行了,这篇博客主要是记录一下hexo的升级过程。
hexo升级
全局升级hexo-cli,先hexo version查看当前版本,然后npm install -g hexo-cli,再次hexo version查看是否升级成功。
1
2npm install -g hexo-cli
hexo version全局安装npm-check,用于检测是否有需要升级的依赖。安装成功后,可以使用
npm-check -u命令,按照提示选择要升级的依赖。1
2npm install -g npm-check
npm-check -u
依赖成功升级后,发现项目并不能正常启动,提示
_comfig.yml中存在无效配置。原因是版本跨度太大,有些配置规范已经被修改了,需要按照官网最新的配置规则进行修改。_comfig.yml修改后,hexo终于可以正常启动了,但是预览发现网页不能被正常解析(如下图),因为我之前使用的主题next也需要升级到最新版本才能适配。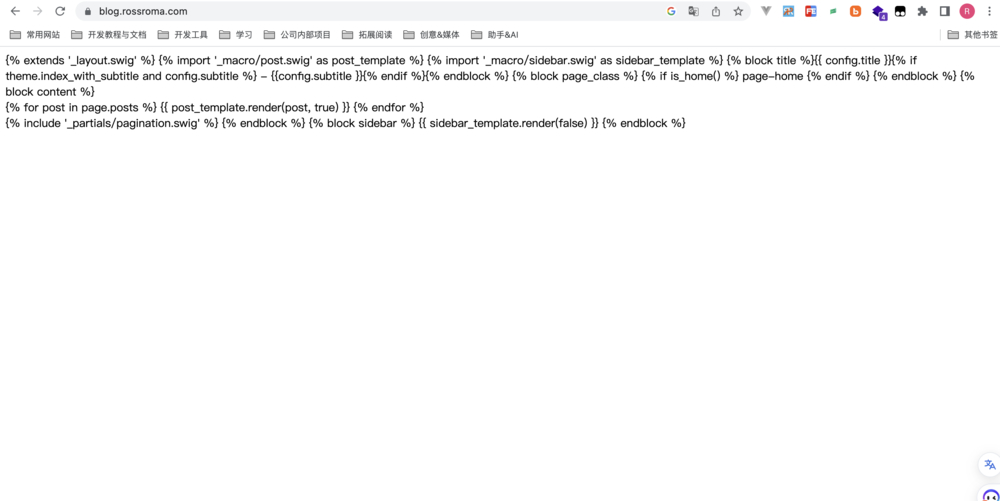
主题升级文档地址:https://theme-next.js.org/docs/getting-started/upgrade.html
第一步:将原来themes目录下的老主题目录进行备份;
第二步:用
npm install hexo-theme-next安装新的主题;第三步:对主题进行配置修改,将
node_modules/hexo-theme-next/_config.yml文件拷贝到根目录,然后重命名为_config.next.yml,再将之前备份的主题配置还原到新的配置文件中。主题升级完成,启动后预览,发现主题的语言包不是中文,我检查了一下配置文件,之前设置的默认语言是
language: zh-Hans,在新版的hexo中简体中文已经改成了zh-CN,与i18n标准保持一致了。
hexo部署
当我以为hexo已经全部升级完成时,部署又遇到了一些坑
首先就是运行
hexo d抛出异常,提示Error: EACCES: permission denied, unlink,一般Mac遇到这个问题,就是文件权限的问题,解决方案是删除.deploy_git目录,然后重新部署1
2
3
4
5
6删除项目根目录下的 .deploy_git
sudo rm -rf .deploy_git
hexo clean
hexo g
hexo d之后运行
hexo d部署发现又失败了,原因是_config.yml中的repo最好使用ssh地址,使用http地址就会有一定的失败概率;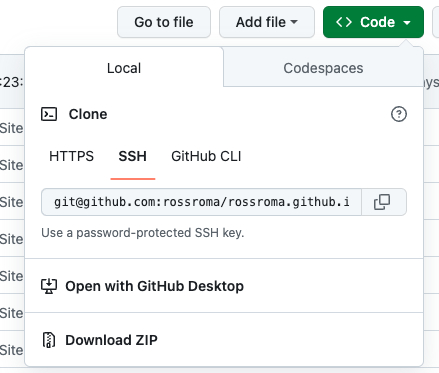
1
2
3
4
5
6Deployment
# Docs: https://hexo.io/docs/deployment.html
deploy:
type: git
repo: git@github.com:rossroma/rossroma.github.io.git
branch: master最后hexo终于被推送到github了,发现里面的图片全部无法显示了,因为现在大部分网站都已经升级了https,已经无法加载http协议的图片了。由于我的博客搭建的比较早,那时候都还在用http协议的图片,无奈,还要把图片升级一下。
我的图片都存储在七牛,如果有备案域名的话,可以免费申请一个https证书,过程比较简单,就不赘述了。
我顺便还给Typora配置了图床,如图:
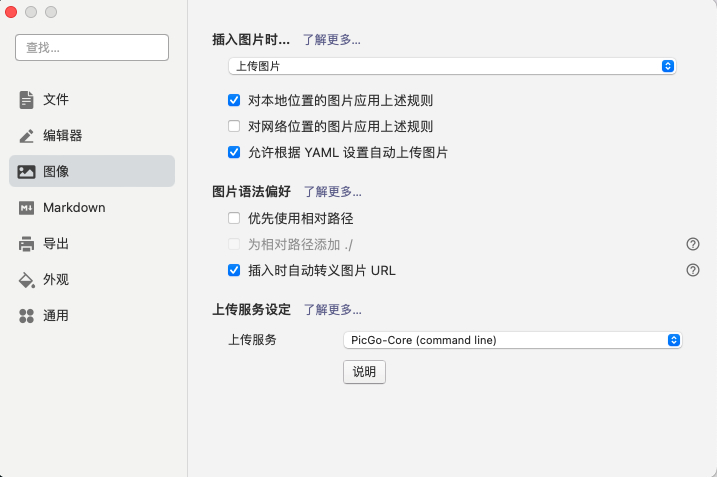
用的是PicGo,配置比较简单,有中文的说明文档,感兴趣的可以去看一下:https://picgo.github.io/PicGo-Doc/。配置好之后,在Typora中插入图片会自动上传到七牛并将URL替换,用起来非常丝滑。
总结
至此,整个升级过程终于结束了,本来我以为只是简单的升级几个依赖,后面却发现耗费了我半天的时间。因此值得写篇文章,记录一下这个过程。